期刊: ISA Transactions(IF:7.3)
创新点
- 提出了一种新颖的部分迁移故障诊断网络,以减轻源域和目标域之间标签空间相同的限制。
- 提出了一种新的视角,即增强目标域,使源域和目标域平衡,以减少负面影响。
- 联合进行边际和条件排列,以提取域不变和类区分特征。
相关技术
Domain adaption with adversarial network(DANN)
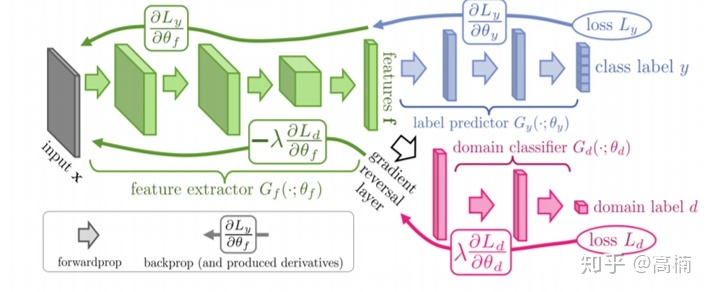
DANN结构主要包含3个部分:
- 特征提取器 (feature extractor) - 图示绿色部分,用来将数据映射到特定的特征空间,使标签预测器能够分辨出来自源域数据的类别的同时,域判别器无法区分数据来自哪个域。
- 标签预测器 (label predictor) - 图示蓝色部分,对来自源域的数据进行分类,尽可能分出正确的标签。
- 域判别器(domain classifier)- 图示红色部分,对特征空间的数据进行分类,尽可能分出数据来自哪个域。
其中,特征提取器和标签分类器构成了一个前馈神经网络。然后,在特征提取器后面,我们加上一个域判别器,中间通过一个梯度反转层 (gradient reversal layer, GRL) 连接。在训练的过程中,对来自源域的带标签数据,网络不断最小化标签预测器的损失 (loss)。对来自源域和目标域的全部数据,网络不断最小化域判别器的损失。
那么在训练阶段我们要做的是如下两个任务:
第一个则是实现源域数据集准确分类,实现现图像分类误差的最小化;
第二个任务则是要混淆源域数据集和目标域数据集,实现域分类误差的最大化,
标签预测器的损失
对于特征提取器 (以单隐层为例),sigmoid作为激活函数,其输出为:
$G_f(x;\bold{W},\bold{b}) = \rm sigm(\bold{W}x+\bold{b})$
对于标签预测器,softmax作为激活函数,其输出为:
$G_y(G_f(x); \bold{V},\bold{c}) = \rm softmax(\bold{V}G_f(x)+\bold{c})$
当给定数据点$(x_i, y_i)$,负对数似然 (negative log-probabality) 作为损失函数,其标签预测器的损失为:
$\mathcal{L}y(G_y(G_f(x_i)),y_i)=\rm log \frac{1}{G_y(G_f(x))}{y_i}$
因此在源域上,我们的训练优化目标就是:
$\min_{\mathbf{W,b,V,c} }=\left [ \frac{1}{n}\sum_{i=1}^{n} \mathcal{L}^i_y(\mathbf{W,b,V,c})+\lambda \cdot R(\mathbf{W,b})\right ] $
其中, $\mathcal{L}^i_y$表示第 $i$ 个样本的标签预测损失,$R(W,b)$是一个可选的正则化器(Regularizer), $\lambda$是人为设置的正则化参数,$\lambda \cdot R(W,b)$目的是用来防止神经网络过拟合。
标签预测器的损失表达函数现在讲完了,和其他普通神经网络差不多。然而,DANN网络的核心主要在接下来要讲的部分:跨域正则器(Domain Regularizer)。
域判别器损失
对于域判别器,sigmoid作为激活函数,其输出为:
$G_{d}\left(G_{f}(\mathbf{x}) ; \mathbf{u}, z\right)=\operatorname{sigm}\left(\mathbf{u}^{\top} G_{f}(\mathbf{x})+z\right)$
然后,我们定义域判别器 $G_d(\cdot)$ 的损失为 (负对数似然作为损失函数):
$\mathcal{L}{d}\left(G{d}\left(G_{f}\left(\mathbf{x}{i}\right)\right), d{i}\right)=d_{i} \log \frac{1}{G_{d}\left(G_{f}\left(\mathbf{x}{i}\right)\right)}+\left(1-d{i}\right) \log \frac{1}{G_{d}\left(G_{f}\left(\mathbf{x}_{i}\right)\right)}$
$d_i$ 表示第 $i$个样本的二元标签,用来表示这个样本属于源域还是目标域。此时,域判别器的目标函数为
$R(\mathbf{W}, \mathbf{b})=\max {\mathbf{u}, z}\left[-\frac{1}{n} \sum{i=1}^{n} \mathcal{L}{d}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{u}, z)-\frac{1}{n^{\prime}} \sum{i=n+1}^{N} \mathcal{L}_{d}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{u}, z)\right]$
总损失
对抗迁移网络的总损失由两部分构成:网络的训练损失(标签预测器损失)和域判别损失。
在这里,我们可以给出DANN的总目标函数为:
$E(\mathbf{W}, \mathbf{V}, \mathbf{b}, \mathbf{c}, \mathbf{u}, z)=\frac{1}{n} \sum_{i=1}^{n} \mathcal{L}{y}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{V}, \mathbf{c})-\lambda\left(\frac{1}{n} \sum{i=1}^{n} \mathcal{L}{d}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{u}, z)+\frac{1}{n{i}^{\prime}} \sum_{i=n+1}^{N} \mathcal{L}_{d}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{u}, z)\right)$
其中,我们通过最小化目标函数来更新标签预测器的参数,最大化目标函数来更新域判别器的参数。
$(\hat{\mathbf{W}}, \hat{\mathbf{v}}, \hat{\mathbf{b}}, \hat{\mathbf{c}})=\underset{\mathbf{w}, \mathbf{v}, \mathbf{b}, \mathbf{c}}{\operatorname{argmin}} E(\mathbf{w}, \mathbf{v}, \mathbf{b}, \mathbf{c}, \hat{\mathbf{u}}, \hat{z})$
$(\hat{\mathbf{u}}, \hat{z})=\underset{\mathbf{u}, z}{\operatorname{argmax}} E(\hat{\mathbf{W}}, \hat{\mathbf{v}}, \hat{\mathbf{b}}, \hat{\mathbf{c}}, \mathbf{u}, z)$
方法
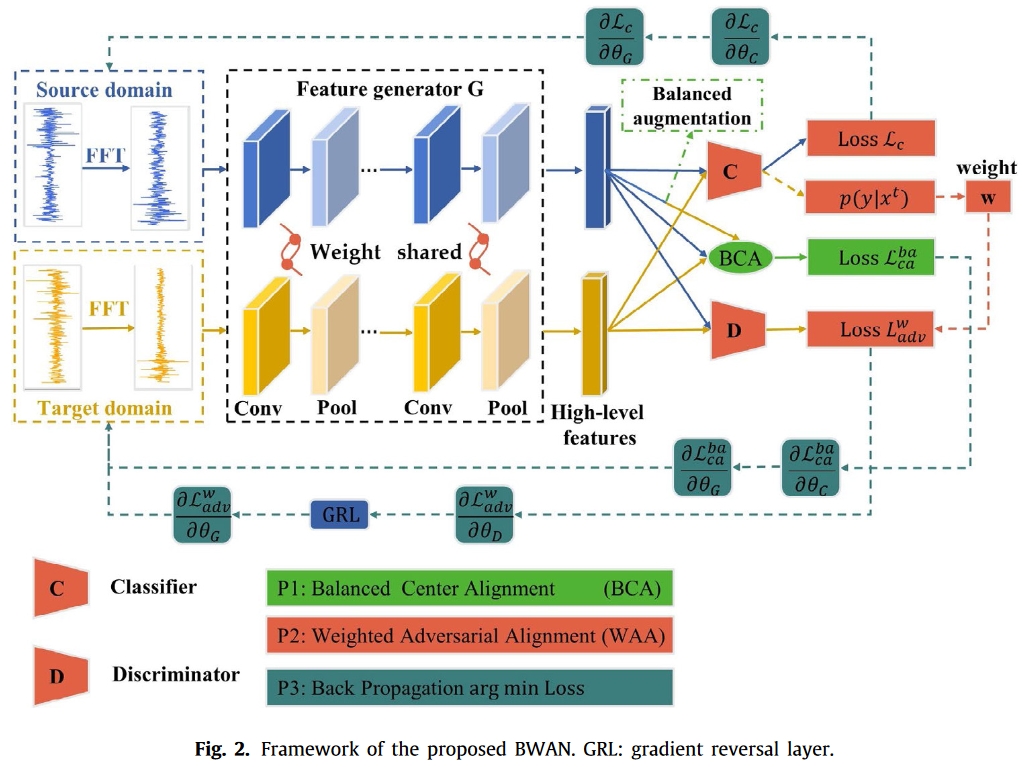
本节将详细介绍提出的部分转移故障诊断网络。在 PTFD 问题中,源类别与目标类别是不对称的。因此,源标签空间可自然划分为共享空间(与目标标签空间相同)和离群空间(与目标标签空间无关)。图 2 展示了拟议的 BWAN 的总体诊断框架。除了输入数据和特征生成器外,还可以看到有三种颜色(绿色、橙色、瓶绿),分别对应三个部分。
第一部分(绿色部分)是平衡中心对齐(BCA),用于增强目标域并对齐条件分布。
第二部分(橙色部分)是加权对抗对齐(WAA),在对抗训练中嵌入加权策略。
第三部分(绿色瓶子部分)是目标函数优化,使用梯度下降算法找到最佳参数。接下来将详细介绍所设计的网络和三个部分。
结构细节
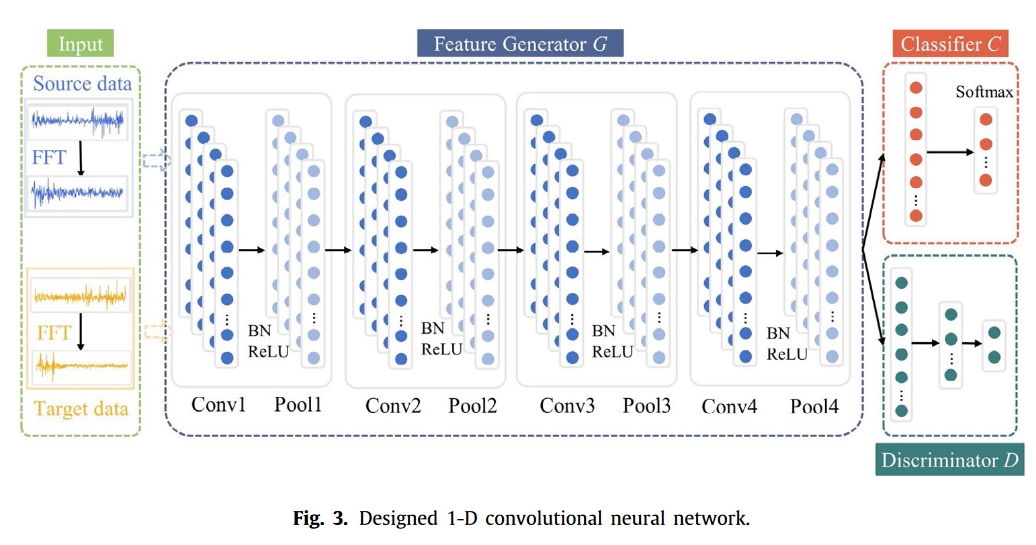
网络架构由特征生成器 G、故障分类器 C 和域判别器 D 组成,如图 3 所示。
一维卷积神经网络(1D-CNN)具有卓越的特征提取能力,可作为特征生成器,自动从两个域的原始输入中学习更深、更好的表征。
分类器 C 参与机器状态分类,并学习如何对源给定样本做出决策。同时,判别器 D 作为助手,对源进行判别。
判别器 D 可以帮助特征生成器 G 学习到更好的领域不变表征,从而提高 C 对目标任务的预测精度。
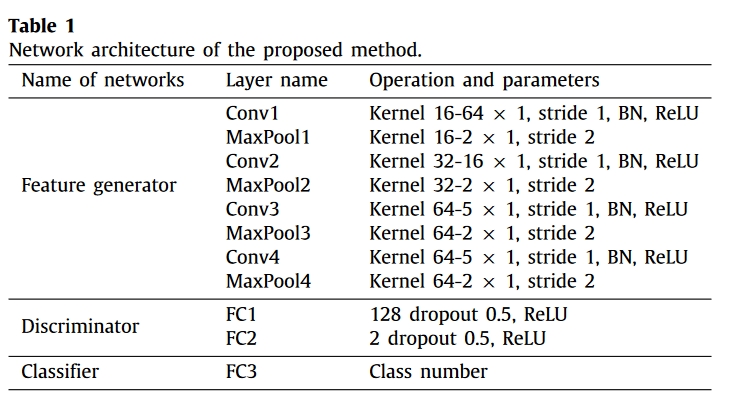
表 1 列出了提出架构的详细信息。为了避免在训练过程中出现过拟合,我们采用了正则化技术 Dropout(实验比率为 0.5)。通过重新居中和重新缩放,批量归一化(BN)加速了计算并稳定了训练过程。
平衡中心对齐
作为一种不对称和不平衡的转移场景,现有的领域自适应方法不可避免地会使目标类别与源异常类别不匹配,从而导致负转移,降低诊断精度。因此,提出了由平衡增广和中心对准组成的平衡中心对准,以避免域自适应中源异常值引起的失配,并获得类判别特征。
为了缓解非对称类跨域引起的负迁移,我们通过增强目标域来寻求不同标签分布之间的平衡。具体而言,平衡增广从源域随机均匀地选择几个标记样本,并在平衡中心对准期间将它们设置为增广目标类别的伪目标样本,如图4所示。
随机均匀采样保证了域自适应中源域和增广目标域之间的类别一致性,从而减少了概率分布的差异,从而将部分转移问题转化为一个研究得很好的转移问题。
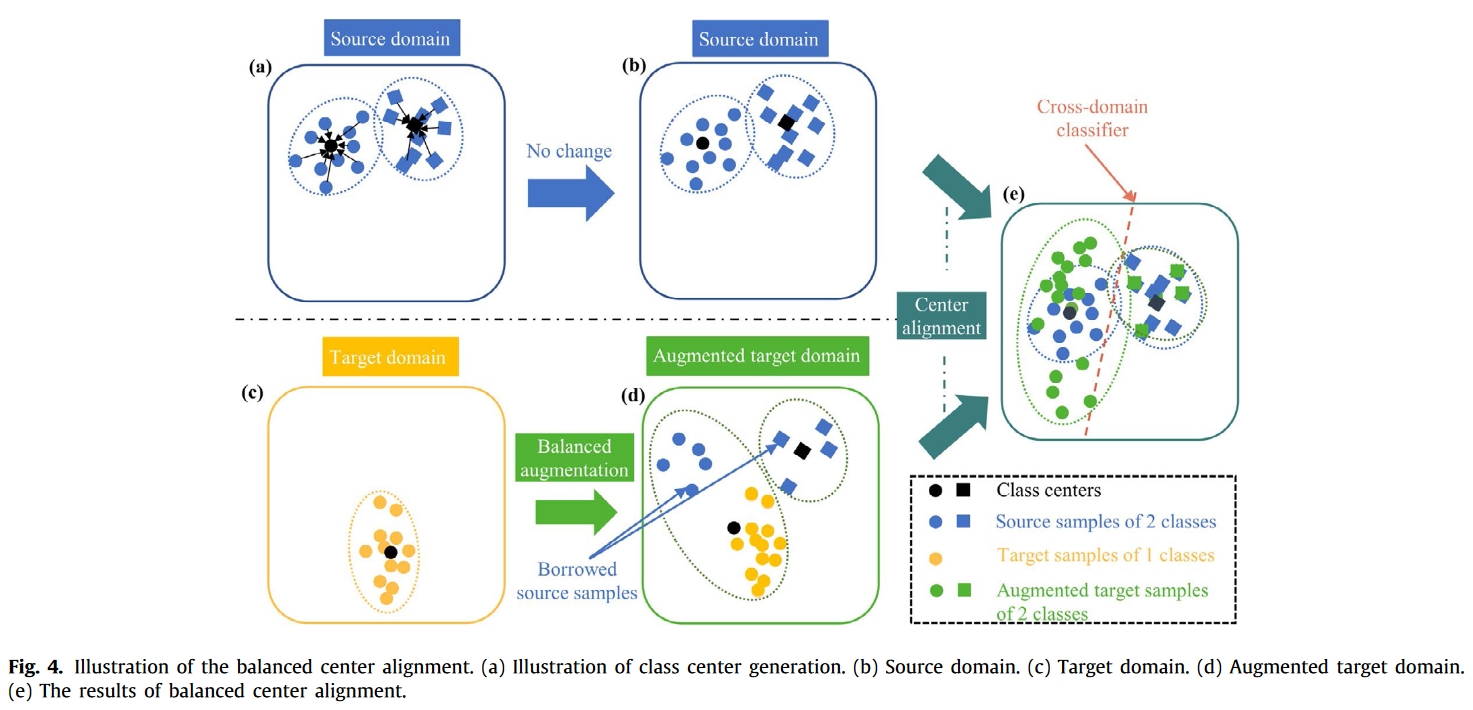
从源域借用的伪目标样本有望同时补充目标离群分布和维持目标共享分布。在本研究中,我们采用网格搜索策略来确保最优增殖比 ε,ε 定义为:
$\varepsilon = \frac{\sum_{j=1}^{|y_s|}|X_{st}^j|}{\sum_{j=1}^{|y_s|}|X_{st}^j|+\sum_{j=1}^{|y_t|}|X_t^j|} $
其中,$|y_s|$ 和 $|y_t |$ 分别表示源域和目标域的机器健康状态数。$X^j_t$ 和$ X^j_s$ 分别表示原始目标域第 j 个类集和借用源域第 j 个类集。
由于中心可以代表类的平均分布特性,因此中心的差异可以表征类的分布偏移。因此,我们缩短了源域和增强目标域之间一对类中心的距离,使两个域的类中心对齐。这样,两个域中相同的类样本就会被拉近,两个域中的类分布就会变得相似,也就是实现了两个域之间的条件分布对齐。平衡中心配准 $L^{ba}_{ca}$ 的详细公式定义如下
$\mathcal{L}{ca}^{ba}(\theta_G,\theta_C)=\sum{j=1}^{|y_s|}\psi\left(\mathbf{c}s^j,\mathbf{c}{t_{-au}}^j\right)$
其中,$C^j_s$ 和 $C^j_{t_au}$ 分别是源域和增强目标域的第 j 个类中心。$ψ(\cdot, \cdot)$ 为欧氏距离。源样本与标签相关联,因此可以准确计算出第 j 个源类中心、
$C_s^j=\frac1{|X_s^j|}\sum_{(\mathbf{x}_i,y_i)\in X_s^j}G\left(\mathbf{x}_i\right)$
其中$X^j_s$表示标签为j的源域集合。在平衡扩充之后,第j个扩充目标类由原始目标样本和来自源域的扩充样本组成。由于缺乏原始目标特征的标签,使用伪标签$\hat{y}$(模型的最大激活目标输出)来计算相应的目标类中心。给定原始目标域第j类集合$X^j_t$和借用源域第j类别集合$X^j_{st}$,就可以得到类中心 $C^j_{ t_au}$:
$C_{t_ba}^j=\frac1{|X_t^j|+|X_{st}^j|}(\sum_{(\mathbf{x}_i,\hat{y}_i)\in X_t^j}G\left(\mathbf{x}i\right)+\sum{(\mathbf{x}i,y_i)\in X{st}^j}G\left(\mathbf{x}_i\right))$
在平衡中心对齐过程中,我们仅从源域向目标域借用原始样本,以降低不匹配风险,并帮助减轻异常值带来的负面影响。
Weighted adversarial alignment
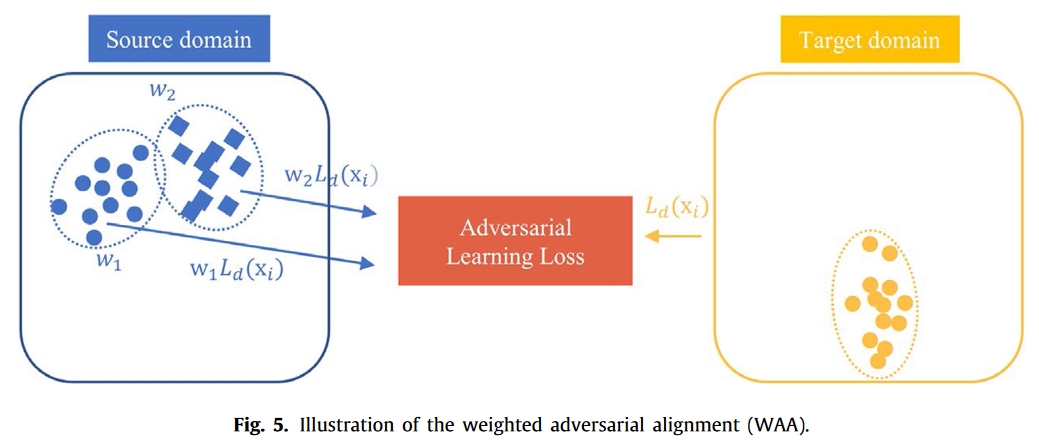
与扩展目标域相反,另一个合理的角度是检测和过滤分布对齐中的源异常值。然而,目标样本是无标记的,因此无法直接知道目标域中存在哪些故障。幸运的是,我们观察到分类器对每个源样本的输出提供了源标签空间的概率分布。由于源离群空间和目标标签空间是不相交的,因此将目标样本分配到源离群空间的概率应该足够小。
因此,目标样本的概率输出$\hat{y}^t_i$可以量化每个源类别的重要性。因此,本研究采用了能有效显示各源类别贡献的类别级权重:
$w=\frac1{n_t}\sum_{i=1}^{n_t}\hat{y}i^t=\frac1{n_t}\sum{i=1}^{n_t}p(y|x^t),$
其中,$w$ 是一个$|y_s|$ 维权重向量,$n_t$ 是目标样本数。为了显示类别的相对重要性,我们将类别级权重$ w$ 归一化,除以最大元素,即 $w ← w/max(w)$。
接下来,我们将标准对抗式配准增强为加权对抗式配准(WAA),方法是在领域判别器中添加类级权重 w,以关注共享类。加权学习策略可以区分不同源类的重要程度,即源离群类的权重将明显小于共享类的权重,从而消除负迁移,促进正迁移。需要注意的是,源域只在加权对抗配准过程中加权。
图 5 展示了所提出的加权对抗式配准方案,在对抗式学习中,不同的源类被赋予不同的权重。加权对抗配准函数的具体目标定义为
$\begin{aligned}L_{adv}^w\left(\theta_G,\theta_D,\theta_C\right)&=\frac1{n_s}\sum_{\mathbf{x}i\in\mathcal{D}S}L{GE}(C(G(\mathbf{x}i)),y_i)\&-\frac\alpha{n_s}\sum{j=1}^{|\mathcal{N}|}\sum{\mathbf{x}_i\in\mathcal{D}s^j}w_jL{CE}(D\left(G(\mathbf{x}i)\right),d_i)\&-\frac\alpha{n_t}\sum{\mathbf{x}_t\in\mathcal{D}t}L{GE}(D\left(G(\mathbf{x}_l)\right),d_i),\end{aligned}$
其中,wj 表示源域的第 j 个类别权重。我们利用熵最小化原理[36]进一步完善分类器,以鼓励类别之间的低密度分离。
$E\left(\theta_G,\theta_C\right)=\frac1{n_t}\sum_{x_i\in\mathcal{D}_t}H(C(G(\mathbf{x}_i))),$
其中,$H(\cdot)$ 是一个信息函数。$H(C (G(x_i))) = - ∑^{|ys|}{j=1} \hat{y}^t{i,j}log \hat{y}^t_{i,j}$。通过最小化公式 (9),分类器可以获取目标非标记数据,以最小的预测不确定性和稳定的决策边界输出更精确的概率$\hat{y}^t_i$。
目标函数优化和诊断步骤
结合公式 (4)、(8) 和 (9) 的优化目标,拟议方法的总体目标可写为:
$\begin{aligned}\mathcal{L}\left(\theta_G,\theta_D,\theta_C\right)&=\frac1{n_s}\sum_{x_i\in\mathcal{D}s}L{GE}(\mathcal{C}\left(G(x_i)\right),y_i)\&-\frac\alpha{n_s}\sum_{j=1}^{|\mathcal{V}s|}\sum{x_i\in\mathcal{D}s^j}w_jL{CE}(D\left(G(x_i)\right),d_s)\&-\frac\alpha{n_t}\sum_{x_i\in\mathcal{D}t}L{CE}(D\left(G(x_i)\right),d_t)\&+\beta\sum_{k=1}^K\psi\left(\mathbf{C}s^j,\mathbf{C}{t_{ba}}^j\right)\&+\gamma\frac1{n_t}\sum_{x_i\in\mathcal{D}_t}H(C(G(\mathbf{x}_i)))\end{aligned} $
其中,$β$ 和 $γ$ 是两个权衡参数,$d_s$ 和 $d_t$ 是源域和目标域标签。网络优化的目的是找到满足以下条件的参数 $\hat{θ}G$、$\hat{θ}C$ 和 $\hat{θ}D$、
$\begin{aligned}&\left(\hat{\theta}_G,\hat{\theta}C\right)=\arg\min{\theta_G,\theta_C}\mathcal{L}(\theta_G,\hat{\theta}_D,\theta_C),\&\left(\hat{\theta}D\right)=\arg\max{\theta_D}\mathcal{L}(\hat{\theta}_G,\theta_D,\hat{\theta}_C).\end{aligned}$
我们采用渐进策略来处理 BCA 和 WAA 之间的关系,即随着训练迭代将权衡参数 α 从 0 逐步提高到默认值。主要原因是学习到的特征并不能完全转移,而且类级权重不够精确,无法在早期迭代中过滤掉源样本。BCA 和 WAA 这两种相反的技术在训练过程中互为因果。一方面,通过对齐类中心,源域和增强目标域之间的条件分布差异可以最小化,从而提高预测精度。然后,来自分类器的精确类级权重会引导网络减少边际分布差异,并提取与域无关的特征。另一方面,共享类中的优质领域不变特征有助于减少条件分布差异,提取类区分特征。因此,特征生成器能可靠、积极地提取共享类中的可转移表征,而跨域分类器则能准确预测机器的健康状态。
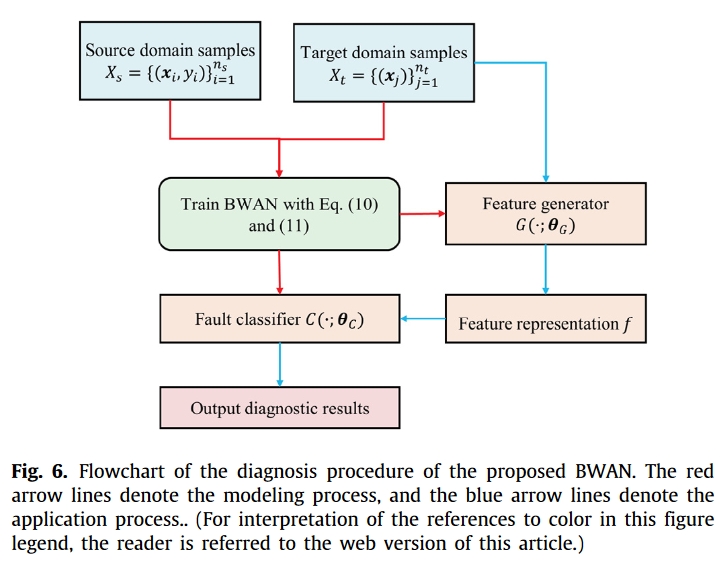
图 6 是提出的 BWAN 流程图。在建模阶段,使用已标记的源样本和未标记的目标样本来训练 BWAN 模型。通过优化目标函数公式 (10) 来学习三个模块的参数,包括特征生成器 G、故障分类器 C 和判别器 D。在应用阶段,首先将目标样本输入参数固定的特征发生器,以获得高级表示 f,这些高级表示已经与源特征分布对齐。最后,高层表示 f 被输入故障分类器,诊断结果由故障分类器的预测决定。
实验
数据集
- KAT. The KAT bearing dataset was provided by Paderborn University.
- PHM09
在这两个数据集中,针对每种健康状况收集了 800 个训练样本和 200 个测试样本。由于频域特征稳定且计算成本较低,因此通过快速傅立叶变换获取频率特性进行建模[39]。
对于 KAT 数据集,每个样本包含 1024 个采样点,并使用前 512 个频率系数。
对于 PHM09 数据集,每个样本包含 6144 个采样点,使用前 4097 个频率系数[40]。
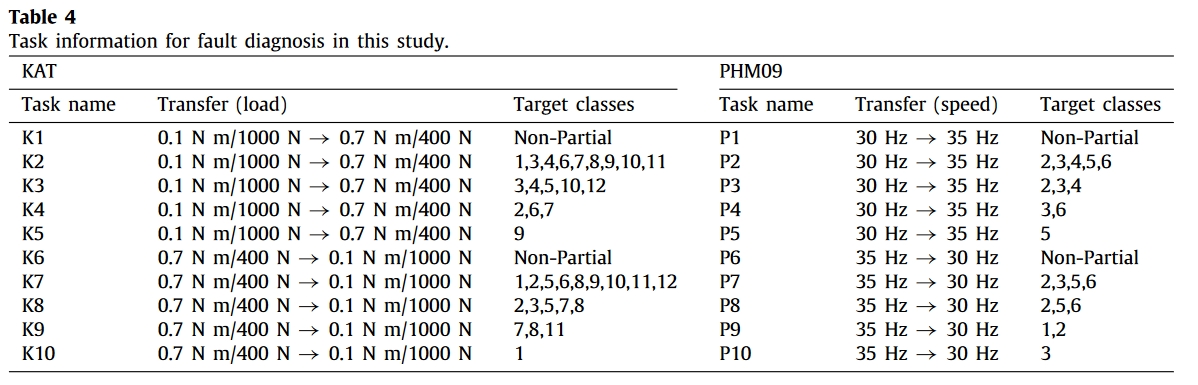
然后,设计了 20 个与非部分故障诊断和部分转移故障诊断相关的任务,以评估所提出的压缩方法的有效性。表 4 列出了诊断任务的详细信息,其中在两个数据集中随机选取了目标机器的健康状态。
对比方法
- 纯监督。首先,采用 Sup-Only(Supervised Only)方法,即只在源域数据上训练故障诊断模型,然后直接在目标域数据上进行测试。
- DA-adv。在 DA-adv(带对抗训练的域适应)方法中,只实施了传统的对抗训练,即调整两个域的边际分布,如第 2.2 节所示。
- 无平衡中心对齐。为了评估平衡中心对齐的益处,我们采用了 No-BCA(无平衡中心对齐)方法,即在建议的方法中去掉 BCA。这意味着模型只配备了加权对抗对齐,如第 3.3 节所述。
- CIDA-2019-TII
- IWAN-2018-IEEE comput soc conf comput vis pattern recognit
实验结果
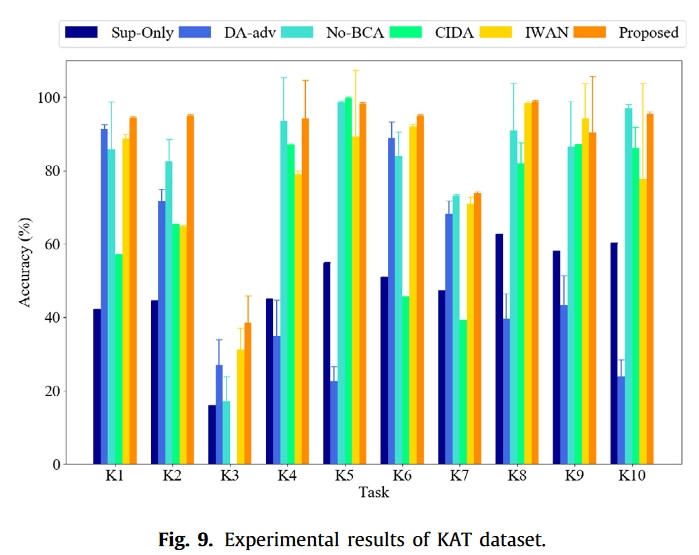
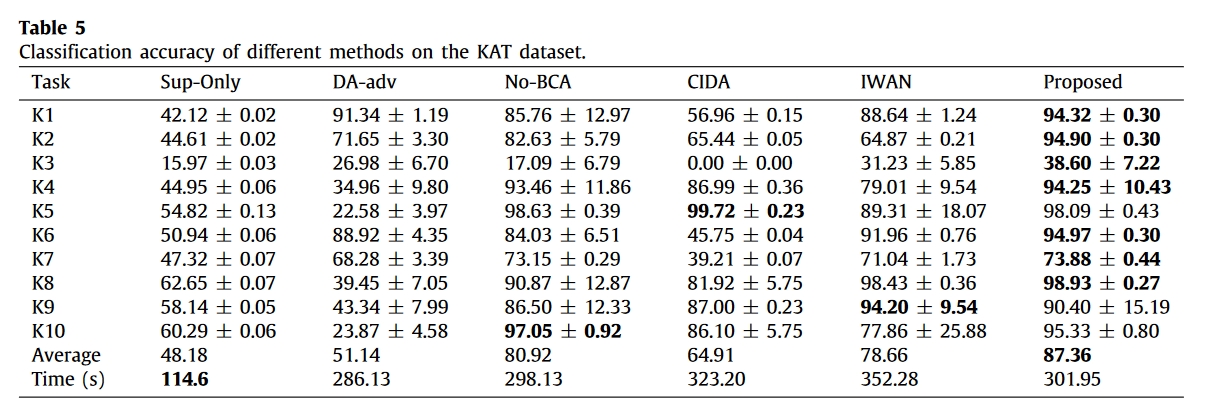
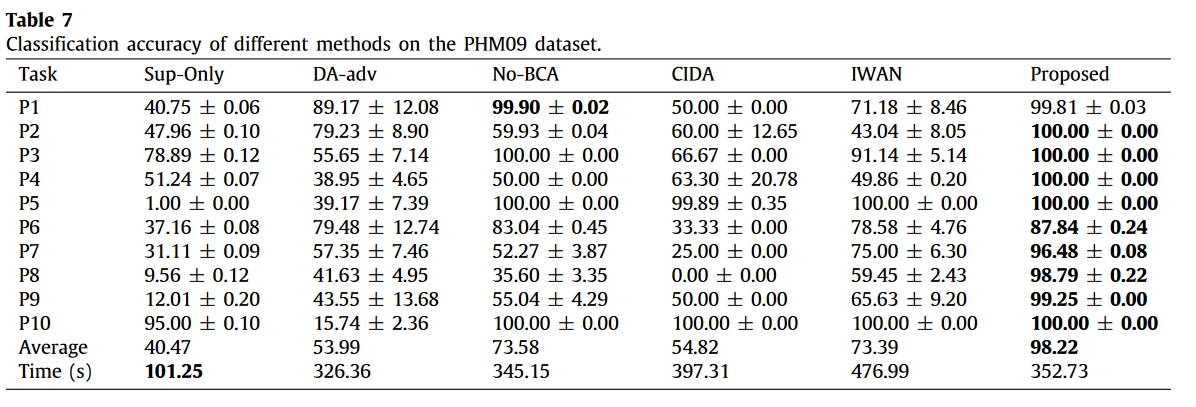
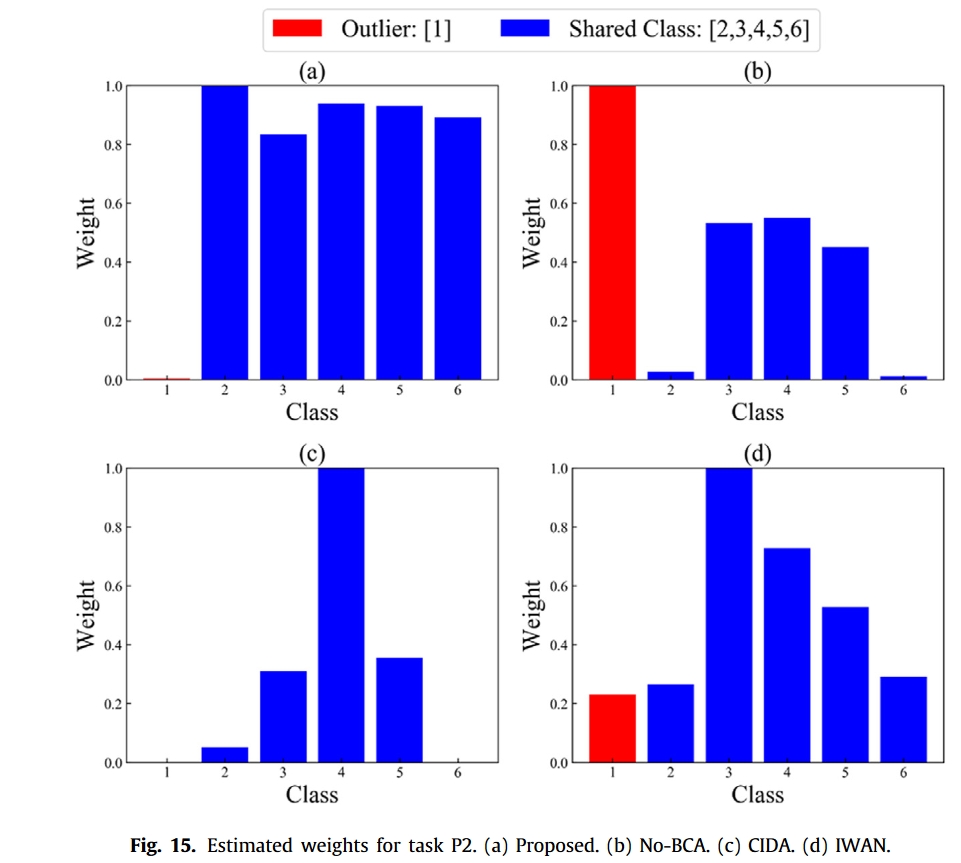
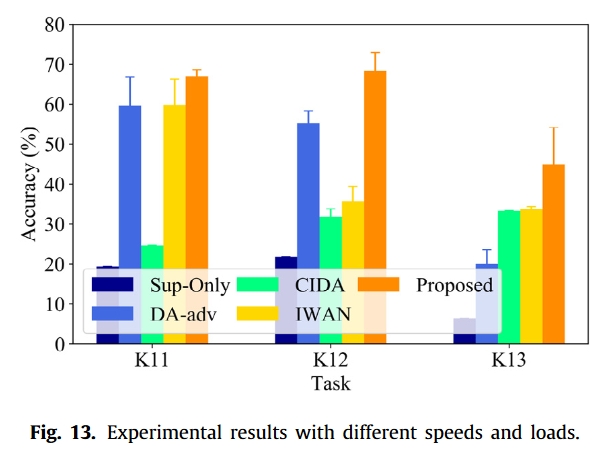
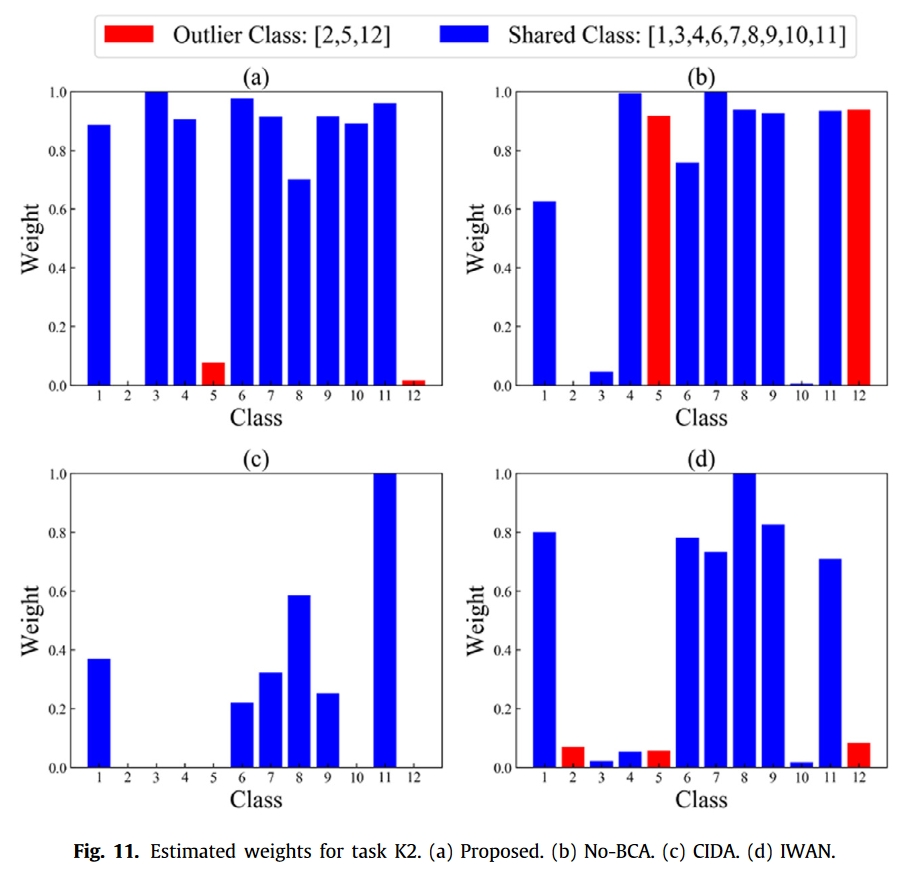
总结
本文提出了一种结构用来解决迁移学习中源域目标域标签不一致的问题。其主要包含两个创新点:
- 平衡中心对齐模块:现有的领域自适应方法不可避免地会使目标类别与源异常类别不匹配,从而导致负转移,降低诊断精度。平衡增广从源域随机均匀地选择几个标记样本,并在平衡中心对准期间将它们设置为增广目标类别的伪目标样本。
- 加权对抗对齐模块:在传统对抗学习的基础上,为每个源域的类别增加权重,使得更好的迁移。